It's AdamW Essay Time again! If you're looking for something short and snappy, look elsewhere.
Kamil Paral kindly informs me I'm a chronic sufferer of Graphomania. Always nice to know what's wrong with you.
IMPORTANT NOTE TO INDUSTRY FOLKS: This blog post is aimed at regular everyday folks; it's intended to dispel a few common myths and help regular people understand UEFI a bit better. It is not a low-level fully detailed and 100% technically accurate explanation, and I'm not a professional firmware engineer or anything like that. If you're actually building an operating system or hardware or something, please don't rely on my simplified explanations or ask me for help; I'm just an idiot on the internet. If you're doing that kind of thing and you have money, join the UEFI Forum or ask your suppliers or check your reference implementation or whatever. If you don't have money, try asking your peers with more experience, nicely. END IMPORTANT NOTE
You've probably read a lot of stuff on the internet about UEFI. Here is something important you should understand: 95% of it was probably garbage. If you think you know about UEFI, and you derived your knowledge anywhere other than the UEFI specifications, mjg59's blog or one of a few other vaguely reliable locations/people - Rod Smith, or Peter Jones, or Chris Murphy, or the documentation of the relatively few OSes whose developers actually know what the hell they're doing with UEFI - what you think you know is likely a toxic mix of misunderstandings, misconceptions, half-truths, propaganda and downright lies. So you should probably forget it all.
Good, now we've got that out of the way. What I mostly want to talk about is bootloading, because that's the bit of firmware that matters most to most people, and the bit news sites are always banging on about and wildly misunderstanding.
Terminology
First, let's get some terminology out of the way. Both BIOS and UEFI are types of firmware for computers. BIOS-style firmware is (mostly) only ever found on IBM PC compatible computers. UEFI is meant to be more generic, and can be found on systems which are not in the 'IBM PC compatible' class.
You do not have a 'UEFI BIOS'. No-one has a 'UEFI BIOS'. Please don't ever say 'UEFI BIOS'. BIOS is not a generic term for all PC firmware, it is a particular type of PC firmware. Your computer has a firmware. If it's an IBM PC compatible computer, it's almost certainly either a BIOS or a UEFI firmware. If you're running Coreboot, congratulations, Mr./Ms. Exception. You may be proud of yourself.
Secure Boot is not the same thing as UEFI. Do not ever use those terms interchangeably. Secure Boot is a single effectively optional element of the UEFI specification, which was added in version 2.2 of the UEFI specification. We will talk about precisely what it is later, but for now, just remember it is not the same thing about UEFI. You need to understand what Secure Boot is, and what UEFI is, and which of the two you are actually talking about at any given time. We'll talk about UEFI first, and then we'll talk about Secure Boot as an 'extension' to UEFI, because that's basically what it is.
Bonus Historical Note: UEFI was not invented by, is not controlled by, and has never been controlled by Microsoft. Its predecessor and basis, EFI, was developed and published by Intel. UEFI is managed by the UEFI Forum. Microsoft is a member of the UEFI forum. So is Red Hat, and so is Apple, and so is just about every major PC manufacturer, Intel (obviously), AMD, and a laundry list of other major and minor hardware, software and firmware companies and organizations. It is a broad consensus specification, with all the messiness that entails, some of which we'll talk about specifically later. It is no one company's Evil Vehicle Of Evilness.
References
If you really want to understand UEFI, it's a really good idea to go and read the UEFI specification. You can do this. It's very easy. You don't have to pay anyone any money. I am not going to tell you that reading it will be the most fun you've ever had, because it won't. But it won't be a waste of your time. You can find it right here on the official UEFI site. You have to check a couple of boxes, but you are not signing your soul away to Satan, or anything. It's fine. As I write this, the current version of the spec is 2.4 Errata A, and that's the version this post is written with regard to.
There is no BIOS specification. BIOS is a de facto standard - it works the way it worked on actual IBM PCs, in the 1980s. That's kind of one of the reasons UEFI exists.
Now, to keep things simple, let's consider two worlds. One is the world of IBM PC compatible computers - hereafter referred to just as PCs - before UEFI and GPT (we'll come to GPT) existed. This is the world a lot of you are probably familiar with and may understand quite well. Let's talk about how booting works on PCs with BIOS firmware.
BIOS booting
It works, in fact, in a very, very simple way. On your bog-standard old-skool BIOS PC, you have one or more disks which have an MBR. The MBR is another de facto standard; basically, the very start of the disk describes the partitions on the disk in a particular format, and contains a 'boot loader', a very small piece of code that a BIOS firmware knows how to execute, whose job it is to boot the operating system(s). (Modern bootloaders frequently are much bigger than can be contained in the MBR space and have to use a multi-stage design where the bit in the MBR just knows how to load the next stage from somewhere else, but that's not important to us right now).
All a BIOS firmware knows, in the context of booting the system, is what disks the system contains. You, the owner of this BIOS-based computer, can tell the BIOS firmware which disk you want it to boot the system from. The firmware has no knowledge of anything beyond that. It executes the bootloader it finds in the MBR of the specified disk, and that's it. The firmware is no longer involved in booting.
In the BIOS world, absolutely all forms of multi-booting are handled above the firmware layer. The firmware layer doesn't really know what a bootloader is, or what an operating system is. Hell, it doesn't know what a partition is. All it can do is run the boot loader from a disk's MBR. You also cannot configure the boot process from outside of the firmware.
UEFI booting: background
OK, so we have our background, the BIOS world. Now let's look at how booting works on a UEFI system. Even if you don't grasp the details of this post, grasp this: it is completely different. Completely and utterly different from how BIOS booting works. You cannot apply any of your understanding of BIOS booting to native UEFI booting. You cannot make a little tweak to a system designed for the world of BIOS booting and apply it to native UEFI booting. You need to understand that it is a completely different world.
Here's another important thing to understand: many UEFI firmwares implement some kind of BIOS compatibility mode, sometimes referred to as a CSM. Many UEFI firmwares can boot a system just like a BIOS firmware would - they can look for an MBR on a disk, and execute the boot loader from that MBR, and leave everything subsequently up to that bootloader. People sometimes incorrectly refer to using this feature as 'disabling UEFI', which is linguistically nonsensical. You cannot 'disable' your system's firmware. It's just a stupid term. Don't use it, but understand what people really mean when they say it. They are talking about using a UEFI firmware's ability to boot the system 'BIOS-style' rather than native UEFI style.
What I'm going to describe is native UEFI booting. If you have a UEFI-based system whose firmware has the BIOS compatibility feature, and you decide to use it, and you apply this decision consistently, then as far as booting is concerned, you can pretend your system is BIOS-based, and just do everything the way you did with BIOS-style booting. If you're going to do this, though, just make sure you do apply it consistently. I really can't recommend strongly enough that you do not attempt to mix UEFI-native and BIOS-compatible booting of permanently-installed operating systems on the same computer, and especially not on the same disk. It is a terrible terrible idea and will cause you heartache and pain. If you decide to do it, don't come crying to me.
For the sake of sanity, I am going to assume the use of disks with a GPT partition table, and EFI FAT32 EFI system partitions. Depending on how deep you're going to dive into this stuff you may find out that it's not strictly speaking the case that you can always assume you'll be dealing with GPT disks and EFI FAT32 ESPs when dealing with UEFI native boot, but the UEFI specification is quite strongly tied to GPT disks and EFI FAT32 ESPs, and this is what you'll be dealing with in 99% of cases. Unless you're dealing with Macs, and quite frankly, screw Macs.
Edit note: the following sections (up to Implications and Complications) were heavily revised on 2014-01-26, a few hours after the initial version of this post went up, based on feedback from Peter Jones. Consider this to be v2.0 of the post. An earlier version was written in a somewhat less accurate and more confusing way.
UEFI native booting: how it actually works - background
OK, with that out of the way, let's get to the meat. This is how native UEFI booting actually works. It's probably helpful to go into this with a bit of high-level background.
UEFI provides much more infrastructure at the firmware level for handling system boot. It's nowhere near as simple as BIOS. Unlike BIOS, UEFI certainly does understand, to varying degrees, the concepts of 'disk partitions' and 'bootloaders' and 'operating systems'.
You can sort of look at the BIOS boot process, and look at the UEFI process, and see how the UEFI process extends various bits to address specific problems.
The BIOS/MBR approach to finding the bootloader is pretty janky, when you think about it. It's very 'special sauce': this particular tiny space at the front of the disk contains magic code that only really makes much sense to the system firmware and special utilities for writing it. There are several problems with this approach.
- It's inconvenient to deal with - you need special utilities to write the MBR, and just about the only way to find out what's in one is to dd the contents out and examine them.
- As noted above, the MBR itself is not big enough for many modern bootloaders. What they do is install a small part of themselves to the MBR proper, and the rest to the empty space on the disk between where the conventional MBR ends and the first partition begins. There's a rather big problem with this (well, the whole design is a big problem, but never mind), which is that there's no reliable convention for where the first partition should begin, so it's difficult to be sure there'll be enough space. One thing you usually can rely on is that there won't be enough space for some bootloader configurations.
- The design doesn't provide any standardized layer or mechanism for selecting boot targets other than disks...but people want to select boot targets other than disks. i.e. they want to have multiple bootable 'things' - usually operating systems - per disk. The only way to do this, in the BIOS/MBR world, is for the bootloaders to handle it; but there's no widely accepted convention for the right way to do this. There are many many different approaches, none of which is particularly interoperable with any of the others, none of which is a widely accepted standard or convention, and it's very difficult to write tooling at the OS / OS installation layer that handles multiboot cleanly. It's just a very messy design.
- The design doesn't provide a standard way of booting from anything except disks. We're not going to really talk about that in this article, but just be aware it's another advantage of UEFI booting: it provides a standard way for booting from, for instance, a remote server.
- There's no mechanism for levels above the firmware to configure the firmware's boot behaviour.
So you can imagine the UEFI Elves sitting around and considering this problem, and coming up with a solution. Instead of the firmware only knowing about disks and one 'magic' location per disk where bootloader code might reside, UEFI has much more infrastructure at the firmware layer for handling boot loading. Let's look at all the things it defines that are relevant here.
EFI executables
The UEFI spec defines an executable format and requires all UEFI firmwares be capable of executing code in this format. When you write a bootloader for native UEFI, you write in this format. This is pretty simple and straightforward, and doesn't need any further explanation: it's just a Good Thing that we now have a firmware specification which actually defines a common format for code the firmware can execute.
The GPT (GUID partition table) format
The GUID Partition Table format is very much tied in with the UEFI specification, and again, this isn't something particularly complex or in need of much explanation, it's just a good bit of groundwork the spec provides. GPT is just a standard for doing partition tables - the information at the start of a disk that defines what partitions that disk contains. It's a better standard for doing this than MBR/'MS-DOS' partition tables were in many ways, and the UEFI spec requires that UEFI-compliant firmwares be capable of interpreting GPT (it also requires them to be capable of interpreting MBR, for backwards compatibility). All of this is useful groundwork: what's going on here is the spec is establishing certain capabilities that everything above the firmware layer can rely on the firmware to have.
EFI system partitions
I actually really wrapped my head around the EFI system partition concept while revising this post, and it was a great 'aha!' moment. Really, the concept of 'EFI system partitions' is just an answer to the problem of the 'special sauce' MBR space. The concept of some undefined amount of empty space at the start of a disk being 'where bootloader code lives' is a pretty crappy design, as we saw above. EFI system partitions are just UEFI's solution to that.1
The solution is this: we require the firmware layer to be capable of reading some specific types of filesystem. The UEFI spec requires that compliant firmwares be capable of reading the FAT12, FAT16 and FAT32 variants of the FAT format, in essence. In fact what it does is codify a particular interpretation of those formats as they existed at the point UEFI was accepted, and say that UEFI compliant firmwares must be capable of reading those formats. As the spec puts it:
"The file system supported by the Extensible Firmware Interface is based on the FAT file system. EFI defines a specific version of FAT that is explicitly documented and testable. Conformance to the EFI specification and its associate reference documents is the only definition of FAT that needs to be implemented to support EFI. To differentiate the EFI file system from pure FAT, a new partition file system type has been defined."
An 'EFI system partition' is really just any partition formatted with one of the UEFI spec-defined variants of FAT and given a specific GPT partition type to help the firmware find it. And the purpose of this is just as described above: allow everyone to rely on the fact that the firmware layer will definitely be able to read data from a pretty 'normal' disk partition. Hopefully it's clear why this is a better design: instead of having to write bootloader code to the 'magic' space at the start of an MBR disk, operating systems and so on can just create, format and mount partitions in a widely understood format and put bootloader code and anything else that they might want the firmware to read there.
The whole ESP thing seemed a bit bizarre and confusing to me at first, so I hope this section explains why it's actually a very sensible idea and a good design - the bizarre and confusing thing is really the BIOS/MBR design, where the only way for you to write something from the OS layer that you knew the firmware layer could consume was to write it into some (but you didn't know how much) Magic Space at the start of a disk, a convention which isn't actually codified anywhere. That really isn't a very sensible or understandable design, if you step back and take a look at it.
As we'll note later, the UEFI spec tends to take a 'you must at least do these things' approach - it rarely prohibits firmwares from doing anything else. It's not against the spec to write a firmware that can execute code in other formats, read other types of partition table, and read partitions formatted with filesystems other than the UEFI variants of FAT. But a UEFI compliant firmware must at least do all these things, so if you are writing an OS or something else that you want to run on any UEFI compliant firmware, this is why the EFI system partition concept is so important: it gives you (at least in theory) 100% confidence that you can put an EFI executable on a partition formatted with the UEFI FAT implementation and the correct GPT partition type, and the system firmware will be able to read it. This is the thing you can take to the bank, like 'the firmware will be able to execute some bootloader code I put in the MBR space' was in the BIOS world.
So now we have three important bits of groundwork the UEFI spec provides: thanks to these requirements, any other layer can confidently rely on the fact that the firmware:
- Can read a partition table
- Can access files in some specific filesystems
- Can execute code in a particular format
This is much more than you can rely on a BIOS firmware being capable of. However, in order to complete the vision of a firmware layer that can handle booting multiple targets - not just disks - we need one more bit of groundwork: there needs to be a mechanism by which the firmware finds the various possible boot targets, and a way to configure it.
The UEFI boot manager
The UEFI spec defines something called the UEFI boot manager. (Linux distributions contain a tool called efibootmgr which is used to manipulate the configuration of the UEFI boot manager). As a sample of what you can expect to find if you do read the UEFI spec, it defines the UEFI boot manager thusly:
"The UEFI boot manager is a firmware policy engine that can be configured by modifying architecturally defined global NVRAM variables. The boot manager will attempt to load UEFI drivers and UEFI applications (including UEFI OS boot loaders) in an order defined by the global NVRAM variables."
Well, that's that cleared up, let's move on. ;) No, not really. Let's translate that to Human. With only a reasonable degree of simplification, you can think of the UEFI boot manager as being a boot menu. With a BIOS firmware, your firmware level 'boot menu' is, necessarily, the disks connected to the system at boot time - no more, no less. This is not true with a UEFI firmware.
The UEFI boot manager can be configured - simply put, you can add and remove entries from the 'boot menu'. The firmware can also (it fact the spec requires it to, in various cases) effectively 'generate' entries in this boot menu, according to the disks attached to the system and possibly some firmware configuration settings. It can also be examined - you can look at what's in it.
One rather great thing UEFI provides is a mechanism for doing this from other layers: you can configure the system boot behaviour from a booted operating system. You can do all this by using the efibootmgr tool, once you have Linux booted via UEFI somehow. There are Windows tools for it too, but I'm not terribly familiar with them. Let's have a look at some typical efibootmgr output, which I stole and slightly tweaked from the Fedora forums:
[root@system directory]# efibootmgr -v
BootCurrent: 0002
Timeout: 3 seconds
BootOrder: 0003,0002,0000,0004
Boot0000* CD/DVD Drive BIOS(3,0,00)
Boot0001* Hard Drive HD(2,0,00)
Boot0002* Fedora HD(1,800,61800,6d98f360-cb3e-4727-8fed-5ce0c040365d)File(\EFI\fedora\grubx64.efi)
Boot0003* opensuse HD(1,800,61800,6d98f360-cb3e-4727-8fed-5ce0c040365d)File(\EFI\opensuse\grubx64.efi)
Boot0004* Hard Drive BIOS(2,0,00)P0: ST1500DM003-9YN16G .
[root@system directory]#
This is a nice clean example I stole and slightly tweaked from the Fedora forums. We can see a few things going on here.
The first line tells you which of the 'boot menu' entries you are currently booted from. The second is pretty obvious (if the firmware presents a boot menu-like interface to the UEFI boot manager, that's the timeout before it goes ahead and boots the default entry). The BootOrder is the order in which the entries in the list will be tried. The rest of the output shows the actual boot entries. We'll describe what they actually do later.
If you boot a UEFI firmware entirely normally, without doing any of the tweaks we'll discuss later, what it ought to do is try to boot from each of the 'entries' in the 'boot menu', in the order listed in BootOrder. So on this system it would try to boot the entry called 'opensuse', then if that failed, the one called 'Fedora', then 'CD/DVD Drive', and then the second 'Hard Drive'.
UEFI native booting: how it actually works - boot manager entries
What does these entries actually mean, though? There's actually a huge range of possibilities that makes up rather a large part of the complexity of the UEFI spec all by itself. If you're reading the spec, pour yourself an extremely large shot of gin and turn to the EFI_DEVICE_PATH_PROTOCOL section, but note that this is a generic protocol that's used for other things than booting - it's UEFI's Official Way Of Identifying Devices For All Purposes, used for boot manager entries but also for all sorts of other purposes. Not every possible EFI device path makes sense as a UEFI boot manager entry, for obvious reasons (you're probably not going to get too far trying to boot from your video adapter). But you can certainly have an entry that points to, say, a PXE server, not a disk partition. The spec has lots of bits defining valid non-disk boot targets that can be added to the UEFI boot manager configuration.
For our purposes, though, lets just consider fairly normal disks connected to the system. In this case we can consider three types of entry you're likely to come across.
BIOS compatibility boot entries
Boot0000 and Boot0004 in this example are actually BIOS compatibility mode entries, not UEFI native entries. They have not been added to the UEFI boot manager configuration by any external agency, but generated by the firmware itself - this is a common way for a UEFI firmware to implement BIOS compatibility booting, by generating UEFI boot manager entries that trigger a BIOS-compatible boot of a given device. How they present this to the user is a different question, as we'll see later. Whether you see any of these entries or not will depend on your particular firmware, and its configuration. Each of these entries just gives a name - 'CD/DVD Drive', 'Hard Drive' - and says "if this entry is selected, boot this disk (where 'this disk' is 3,0,00 for Boot0000 and 2,0,00 for Boot0004) in BIOS compatibility mode".
'Fallback path' UEFI native boot entries
Boot0001 is an entry (fictional, and somewhat unlikely, but it's for illustrative purposes) that tells the firmware to try and boot from a particular disk, and in UEFI mode not BIOS compatibility mode, but doesn't tell it anything more. It doesn't specify a particular boot target on the disk - it just says to boot the disk.
The UEFI spec defines a sort of 'fallback' path for booting this kind of boot manager entry, which works in principle somewhat like BIOS drive booting: it looks in a standard location for some boot loader code. The details are different, though.
What the firmware will actually do when trying to boot in this way is reasonably simple. The firmware will look through each EFI system partition on the disk in the order they exist on the disk. Within the ESP, it will look for a file with a specific name and location. On an x86-64 PC, it will look for the file \EFI\BOOT\BOOTx64.EFI. What it actually looks for is \EFI\BOOT\BOOT{machine type short-name}.EFI - 'x64' is the "machine type short-name" for x86-64 PCs. The other possibilities are BOOTIA32.EFI (x86-32), BOOTIA64.EFI (Itanium), BOOTARM.EFI (AArch32 - that is, 32-bit ARM) and BOOTAA64.EFI (AArch64 - that is, 64-bit ARM). It will then execute the first qualifying file it finds (obviously, the file needs to be in the executable format defined in the UEFI specification).
This mechanism is not designed for booting permanently-installed OSes. It's more designed for booting hotpluggable, device-agnostic media, like live images and OS install media. And this is indeed what it's usually used for. If you look at a UEFI-capable live or install medium for a Linux distribution or other OS, you'll find it has a GPT partition table and contains a FAT-formatted partition at or near the start of the device, with the GPT partition type that identifies it as an EFI system partition. Within that partition there will be a \EFI\BOOT directory with at least one of the specially-named files above. When you boot a Fedora live or install medium in UEFI-native mode, this is the mechanism that is used. The BOOTx64.EFI (or whatever) file handles the rest of the boot process from there, booting the actual operating system contained on the medium.
Full UEFI native boot entries
Boot0002 and Boot0003 are 'typical' entries for operating systems permanently installed to permanent storage devices. These entries show us the full power of the UEFI boot mechanism, by not just saying "boot from this disk", but "boot this specific bootloader in this specific location on this specific disk", using all the 'groundwork' we talked about above.
Boot0002 is a boot entry produced by a UEFI-native Fedora installation. Boot0003 is a boot entry produced by a UEFI-native OpenSUSE installation. As you may be able to tell, all they're saying is "load this file from this partition". The partition is the HD(1,800,61800,6d98f360-cb3e-4727-8fed-5ce0c040365d) bit: that's referring to a specific partition (using the EFI_DEVICE_PATH_PROTOCOL, which I'm really not going to attempt to explain in any detail - you don't necessarily need to know it, if you interact with the boot manager via the firmware interface and efibootmgr). The file is the File(\EFI\opensuse\grubx64.efi) bit: that just means "load the file in this location on the partition we just described". The partition in question will almost always be one that qualifies as an EFI system partition, because of the considerations above: that's the type of partition we can trust the firmware to be able to access.
This is the mechanism the UEFI spec provides for operating systems to make themselves available for booting: the operating system is intended to install a bootloader which loads the OS kernel and so on to an EFI system partition, and add an entry to the UEFI boot manager configuration with a name - obviously, this will usually be derived from the operating system's name - and the location of the bootloader (in EFI executable format) that is intended for loading that operating system.
Linux distributions use the efibootmgr tool to deal with the UEFI boot manager. What a Linux distribution actually does, so far as bootloading is concerned, when you do a UEFI native install is really pretty simple: it creates an EFI system partition if one does not already exist, installs an EFI boot loader with an appropriate configuration - often grub2-efi, but there are others - into a correct path in the EFI system partition, and calls efibootmgr to add an appropriately-named UEFI boot manager entry pointing to its boot loader. Most distros will use an existing EFI system partition if there is one, though it's perfectly valid to create a new one and use that instead: as we've noted, UEFI is a permissive spec, and if you follow the design logically, there's really no problem with having just as many EFI system partitions as you want.
Configuring the boot process (the firmware UI)
The above describes the basic mechanism the UEFI spec defines that manages the UEFI boot process. It's important to realize that your firmware user interface may well not represent this mechanism very clearly. Unfortunately, the spec intentionally refrains from defining how the boot process should be represented to the user or how the user should be allowed to configure it, and what that means - since we're dealing with firmware engineers - is that every firmware does it differently, and some do it insanely.
Many firmwares do have fairly reasonable interfaces for boot configuration. A good firmware design will at least show you the boot order, with a reasonable representation of the entries on it, and let you add or remove entries, change the order, or override the order for a specific boot (by changing it just for that boot, or directly instructing the firmware to boot a particular menu entry, or even giving you the option to simply say "boot this disk", either in BIOS compatibility mode or UEFI 'fallback' mode - my firmware does this). Such an interface will often show 'full' UEFI native boot entries (like the Fedora and openSUSE examples we saw earlier) only by their name; you have to examine the efibootmgr -v output to know precisely what these entries will actually try and do when invoked.
Some firmwares try to abstract and simplify the configuration, and may do a good or a bad job of it. For instance, if you have an option to 'enable or disable' BIOS compatibility mode, what it'll really likely do is configure whether the firmware adds BIOS compatibility entries for attached drives to the UEFI boot manager configuration or not. If you have an option to 'enable or disable' UEFI native booting, what likely really happens when you 'disable' it is that the firmware changes the UEFI boot manager configuration to leave all UEFI-native entries out of the BootOrder.
The key point to remember is that any configuration option inside your firmware interface which is to do with booting is really, behind the scenes, configuring the behaviour of the UEFI boot manager. If you understand all the stuff we've discussed above, you may well find it easier to figure out what's really happening when you twiddle the knobs your firmware interface exposes.
In the BIOS world, you'll remember, you don't always find that systems are configured to try and boot from removable drives - CD, USB - before booting from permanent drives. Some are, and some aren't. Some will try CD before the hard disks, but not USB. People have got fairly used to having to check the BIOS configuration to ensure the boot order is 'correct' when trying to install a new operating system.
This applies to the UEFI world too, but because of the added flexibility/complexity of the UEFI boot manager mechanism, it can look unfamiliar and scary.
If you want to ensure that your system tries to boot from removable devices using the 'fallback' mechanism before it tries to boot 'permanent' boot entries - as you will want to do if you want to, say, install Fedora - you need this to be the default for your firmware, or you need to be able to tell the firmware this. Depending on your firmware's interface, you may find there is a 'menu entry' for each attached removable device and you just have to adjust the boot order to put it at the top of the list, or you may find that there is the mechanism to directly request 'UEFI fallback boot of this particular disk', or you may find that the firmware tries to abstract the configuration somehow. We just don't know, and that makes writing instructions for this quite hard. But now you broadly understand how things work behind the scenes, you may find it easier to understand your firmware user interface's representation of that.
Configuring the boot process (from an operating system)
As we've noted above, unlike in the BIOS world, you can actually configure the UEFI boot process from the operating system level. If you have an insane firmware, you may have to do this in order to achieve what you want.
You can use the efibootmgr tool mentioned earlier to add, delete and modify entries in the UEFI boot manager configuration, and actually do quite a lot of other stuff with it too. You can change the boot order. You can tell it to boot some particular entry in the list on the next boot, instead of using the BootOrder list (if you or some other tool has configured this to happen, your efibootmgr -v output will include a BootNext item stating which menu entry will be loaded on the next boot). There are tools for Windows that can do this stuff from Windows, too. So if you're really struggling to manage to do whatever it is you want to do with UEFI boot configuration from your firmware interface, but you can boot a UEFI native operating system of some kind, you may want to consider doing your boot configuration from that operating system rather than from the firmware UI.
So to recap:
- Your UEFI firmware contains something very like what you think of as a boot menu.
- You can query its configuration with
efibootmgr -v, from any UEFI-native boot of a Linux OS, and also change its configuration with efibootmgr (see the man page for details).
- This 'boot menu' can contain entries that say 'boot this disk in BIOS compatibility mode', 'boot this disk in UEFI native mode via the fallback path' (which will use the 'look for BOOT(something).EFI' method described above), or 'boot the specific EFI format executable at this specific location (almost always on an EFI system partition)'.
- The nice, clean design that the UEFI spec is trying to imply is that all operating systems should install a bootloader of their own to an EFI system partition, add entries to this 'boot menu' that point to themselves, and butt out from trying to take control of booting anything else.
- Your firmware UI has free rein to represent this mechanism to you in whatever way it wants, and it may do this well, or it may do this poorly.
Installing operating systems to UEFI-based computers
Let's have a quick look at some specific consequences of the above that relate to installing operating systems on UEFI computers.
UEFI native and BIOS compatibility booting
Here's a very very simple one which people sometimes miss:
- If you boot the installation medium in 'UEFI native' mode, it will do a UEFI native install of the operating system: it will try to write an EFI-format bootloader to an EFI system partition, and attempt to add an entry to the UEFI boot manager 'boot menu' which loads that bootloader.
- If you boot the installation medium in 'BIOS compatibility' mode, it will do a BIOS compatible install of the operating system: it will try to write an MBR-type bootloader to the magic MBR space on a disk.
This applies (with one minor caveat I'm going to paper over for now) to all OSes of which I'm aware. So you probably want to make sure you understand how, in your firmware, you can choose to boot a removable device in UEFI native mode and how you can choose to boot it in BIOS compatibility mode, and make sure you pick whichever one you actually want to use for your installation.
You really cannot do a completely successful UEFI-native installation of an OS if you boot its installation medium in BIOS compatibility mode, because the installer will not be able to configure the UEFI boot manager (this is only possible when booted UEFI-native).
It is theoretically possible for an OS installer to install the OS in the BIOS style - that is, write a bootloader to a disk's MBR - after being booted in UEFI native mode, but most of them won't do this, and that's probably sensible.
Finding out which mode you're booted in
It is possible that you might find yourself with your operating system installer booted, and not sure whether it's actually booted in UEFI native mode or BIOS compatibility mode. Don't panic! It's pretty easy to find out which, in a few different ways. One of the easiest is just to try and talk to the UEFI boot manager. If what you have booted is a Linux installer or environment, and you can get to a shell (ctrl-alt-f2 in the Fedora installer, for instance), run efibootmgr -v. If you're booted in UEFI native mode, you'll get your UEFI boot manager configuration, as shown above. If you're booted in BIOS compatibility mode, you'll get something like this:
Fatal: Couldn't open either sysfs or procfs directories for accessing EFI variables.
Try 'modprobe efivars' as root.
If you've booted some other operating system, you can try running a utility native to that OS which tries to talk to the UEFI boot manager, and see if you get sensible output or a similar kind of error. Or you can examine the system logs and search for 'efi' and/or 'uefi', and you'll probably find some kind of indication.
Enabling UEFI native boot
To be bootable in UEFI native mode, your OS installation medium must obviously actually comply with all this stuff we've just described: it's got to have a GPT partition table, and an EFI system partition with a bootloader in the correct 'fallback' path - \EFI\BOOT\BOOTx64.EFI (or the other names for the other platforms). If you're having trouble doing a UEFI native boot of your installation medium and can't figure out why, check that this is actually the case. Notably, when using the livecd-iso-to-disk tool to write a Fedora image to a USB stick, you must pass the --efi parameter to configure the stick to be UEFI bootable.
Forcing BIOS compatibility boot
If your firmware seems to make it very difficult to boot from a removable medium in BIOS compatibility mode, but you really want to do that, there's a handy trick you can use: just make the medium not UEFI native bootable at all. You can do this pretty easily by just wiping all the EFI system partitions. (Alternatively, if using livecd-iso-to-disk to create a USB stick from a Fedora image, you can just leave out the --efi parameter and it won't be UEFI bootable). If at that point your firmware refuses to boot it in BIOS compatibility mode, commence swearing at your firmware vendor (if you didn't already).
Disk formats (MBR vs. GPT)
Here's another very important consideration:
- If you want to do a 'BIOS compatibility' type installation, you probably want to install to an MBR formatted disk.
- If you want to do a UEFI native installation, you probably want to install to a GPT formatted disk.
Of course, to make life complicated, many firmwares can boot BIOS-style from a GPT formatted disk. UEFI firmwares are in fact technically required to be able to boot UEFI-style from an MBR formatted disk (though we are not particularly confident that they all really can). But you really should avoid this if at all possible. This consideration is quite important, as it's one that trips up quite a few people. For instance, it's a bad idea to boot an OS installer in UEFI native mode and then attempt to install to an MBR formatted disk without reformatting it. This is very likely to fail. Most modern OS installers will automatically reformat the disk in the correct format if you allow them to completely wipe it, but if you try and tell the installer 'do a UEFI native installation to this MBR formatted disk and don't reformat it because it has data on it that I care about', it's very likely to fail, even though this configuration is technically covered in the UEFI specification. Specifically, Windows and Fedora at least explicitly disallow this configuration.
Checking the disk format
You can use the parted utility to check the format of a given disk:
[adamw@adam Downloads]$ sudo parted /dev/sda
GNU Parted 3.1
Using /dev/sda
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) p
Model: ATA C300-CTFDDAC128M (scsi)
Disk /dev/sda: 128GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 525MB 524MB primary ext4 boot
2 525MB 128GB 128GB primary lvm
(parted)
See that Partition table: msdos? This is an MBR/MS-DOS formatted disk. If it was GPT-formatted, that would say gpt. You can reformat the disk with the other type of partition table by doing mklabel gpt or mklabel msdos from within parted. This will destroy the contents of the disk.
With most OS installers, if you pick a disk configuration that blows away the entire contents of the target disk, the installer will automatically reformat it using the most appropriate configuration for the type of installation you're doing, but if you want to use an existing disk without reformatting it, you're going to have to check how it's formatted and take this into account.
Handling EFI system partition if doing manual partitioning
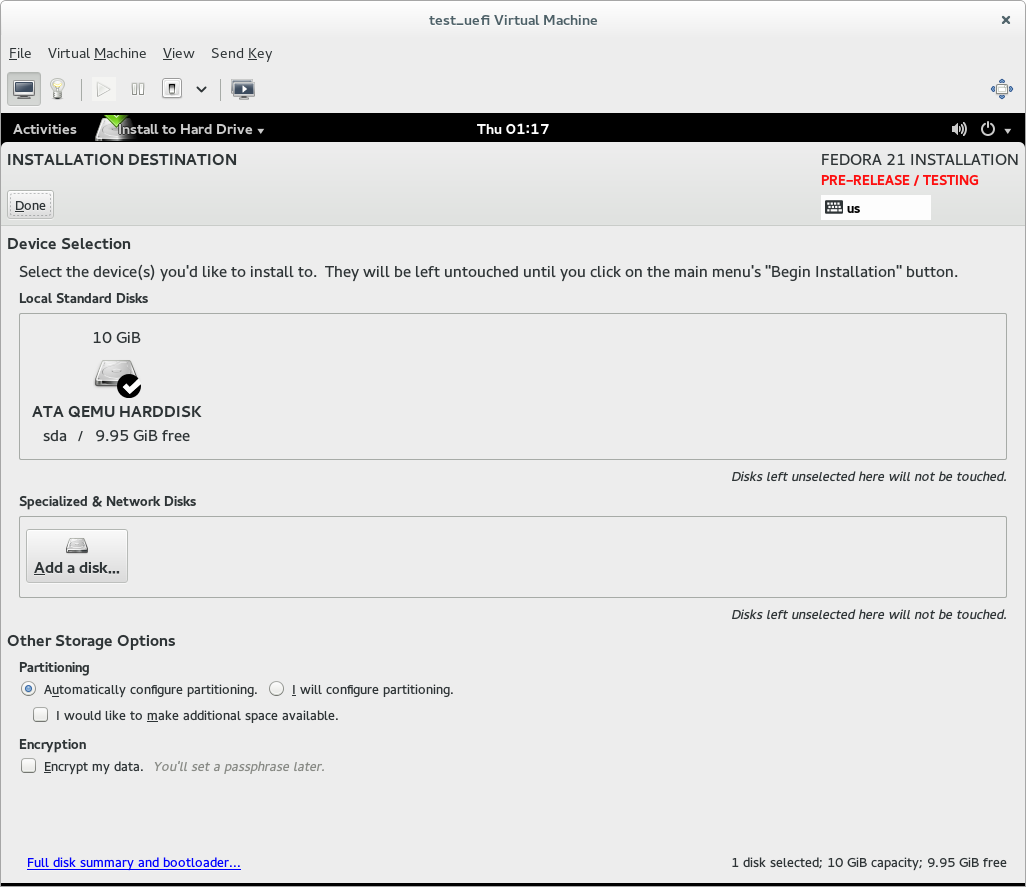
I can only give authoritative advice for Fedora here, but the gist may be useful for other distros / OSes.
If you allow Fedora to handle partitioning for you when doing a UEFI native installation - and you use a GPT-formatted disk, or allow it to reformat the disk (by deleting all existing partitions) - it will handle the EFI system partition stuff for you.
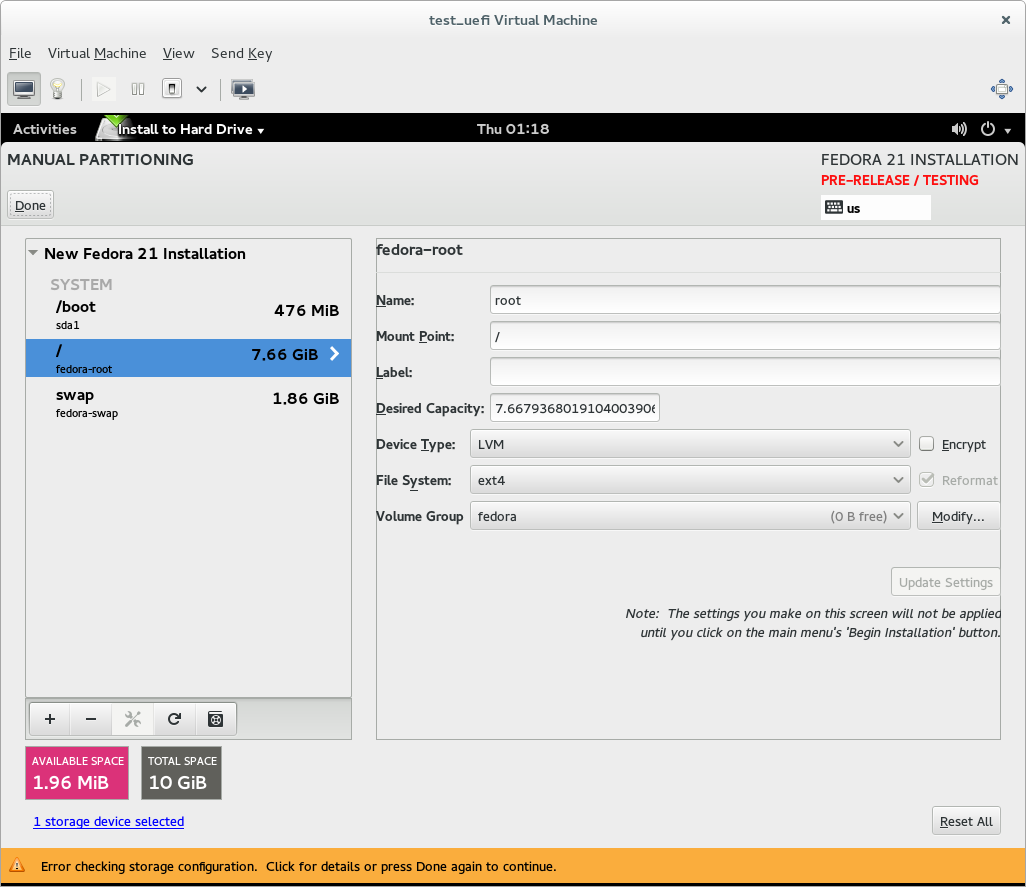
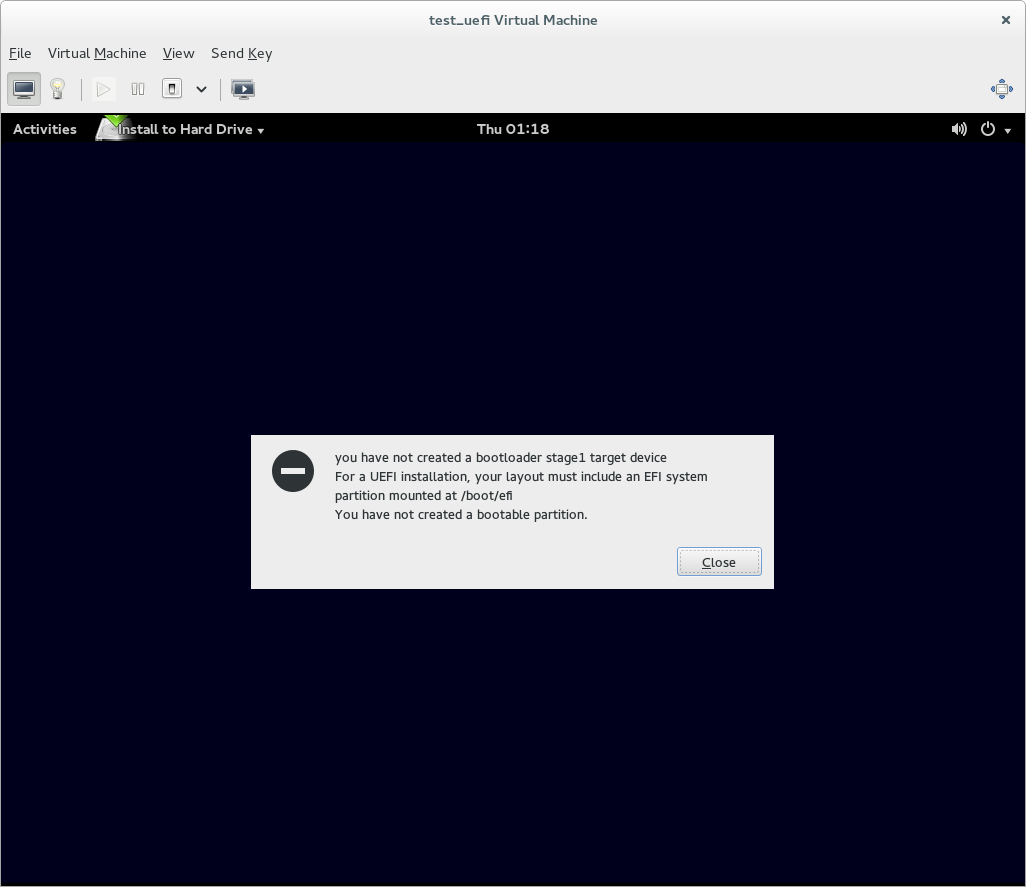
If you use custom partitioning, though, it will expect you to provide an EFI system partition for the installer to use. If you don't do this, the installer will complain (with a somewhat confusing error message) and refuse to let you start the installation.
So if you're doing a UEFI native install and using custom partitioning, you need to ensure that a partition of the 'EFI system partition' type is mounted at /boot/efi - this is where Fedora expects to find the EFI system partition it's using. If there is an existing EFI system partition on the system, just set its mount point to /boot/efi. If there is not an EFI system partition yet, create a partition, set its type to EFI system partition, make it at least 200MB big (500MB is good), and set its mount point to /boot/efi.
A specific example
To boil down the above: if you bought a Windows 8 or later system, you almost certainly have a UEFI native install of Windows to a GPT-formatted disk. This means that if you want to install another OS alongside that Windows install, you almost certainly want to do a UEFI-native installation of your other OS. If you don't like all this UEFI nonsense and want to go back to the good old world you're familiar with, you will, I'm afraid, have to blow away the UEFI-native Windows installation, and it would be a good idea to reformat the disk to MBR.
Implications and Complications
So, that's how UEFI booting works, at least a reasonable approximation. When I describe it like that, it almost all makes sense, right?
However, all is not sweetness and light. There are problems. There always are.
Attentive readers may have noticed that I've talked about the UEFI spec providing a mechanism. This is accurate, and important. As the UEFI spec is a 'broad consensus' sort of thing, one of its major shortcomings (looked at from a particular perspective) is that it's nowhere near prescriptive enough.
If you read the UEFI spec critically, its basic approach is to define a set of functions that UEFI compliant firmwares must support. What it doesn't do a lot of at all is strictly requiring things to be done in any particular way, or not done in any particular way.
So: the spec says that a system firmware must do all the stuff I've described above, in order to be considered a UEFI-compliant firmware. The spec, however, doesn't talk about what operating systems 'should' or 'must' do at all, and it doesn't say that firmwares must not support (or no-one may expect them to support, or whatever)...anything at all. If you're making a UEFI firmware, in other words, you have to support GPT formatted disks, and FAT-formatted EFI system partitions, and you must read UEFI boot manager entries in the standard format, and you must do this and that and the other - but you can also do any other crap you like.
It's pretty easy to read certain implications from the spec - it carefully sets up this nice mechanism for handling OS (or other 'bootable thing') selection at the firmware level, for instance, with the clear implication "hey, it'd be great if all OSes were written to this mechanism". But the UEFI spec doesn't require that, and neither does any other widely-respected specification.
So, what happens in the real world is that we wind up with really dumb crap. Apple, for instance, ships at least some Macs with their bootloaders in an HFS+ partition. The spec says a UEFI-compliant firmware must support UEFI FAT partitions with the specific GPT partition type that identifies them as an "EFI system partition", but it doesn't say the firmware can't also recognize some other filesystem type and load a bootloader from that. (Whether you consider such a partition to be an "EFI system partition" or not is an interesting philosophical conundrum, but let's skate right over that for now).
The world would pretty clearly be a better place if everyone just damn well used the EFI system partition format the spec goes to such great pains to define, but Apple is Apple and we can't have nice things, so Apple went right ahead and wrote firmwares that also can read and load code from HFS+ partitions, and now everyone else has to deal with that or tell Macs to go and get boned. Apple also goes quite a long way beyond the spec in its boot process design, and if you want your alternative OS to show up on its graphical boot menu with a nice icon and things, you have to do more than what the UEFI spec would suggest.
There are various similar incredibly annoying corner cases we've come across, but let's not go into them all right now. This post is long enough.
Also, as we noted earlier, the spec makes no requirements as to how the mechanism should be represented to the user. So if a couple of software companies write OSes to behave 'nicely' according to the conventions the spec is clearly designed to back, and install EFI boot loaders and define EFI boot manager entries with nice clear names - like, oh say, "Fedora" and "Windows" - they are implicitly relying on the firmware to then give the user some kind of sane interface somewhere relatively discoverable that lets them choose to boot "Windows" or "Fedora". The more firmwares don't do a good job of this, the less willing OS engineers will be to rely on the 'proper' conventions, and the more likely they'll be to start rebuilding ugly hacks above the firmware level.
To be fair, we could do somewhat more at the OS level. We could present all those neat efibootmgr capabilities rather more obviously - we can use that 'don't respect BootOrder on the next boot, but instead boot this' capability, for instance, and have 'Reboot to Windows' as an option. It'd be kinda nice if someone looked at exposing all this functionality somewhere more obvious than efibootmgr. Windows 8 systems do use this, to some extent - you can reboot your system to the firmware UI from the Windows 8 settings menus, for instance. But still.
All this is really incredibly frustrating, because UEFI is so close to making things really a lot better. The BIOS approach doesn't provide any kind of convention or standard for multibooting at all - it has to be handled entirely above the firmware level. We (the industry) could have come up with some sort of convention for handling multiboot, but we never did, so it just became a multiple-decade epic fail, where each operating system came up with its own approach and lots of people wrote their own bootloaders which tried to subsume all the operating systems and all the operating systems and independent bootloaders merrily fought like cats in a sack. I mean, pre-UEFI multibooting is such a clusterf**k it's not even worth going into, it's broken sixteen ways from Sunday by definition.
If UEFI - or a spec built on top of it - had just mandated that everybody follow the conventions UEFI carefully establishes, and mandated that firmwares provide a sensible user interface, the win would have been epic. But it doesn't, so it's entirely possible that in a UEFI world things will be even worse than they were in the BIOS world. If many more firmwares show up that don't present a good UI for the UEFI boot manager mechanism, what could happen is that OS vendors give up on the UEFI boot manager mechanism (or decide to support it and alternatives, because choice!) and just reinvent the entire goddamn nightmare of BIOS multibooting on top of UEFI - and we'll all have to deal with all of that, plus the added complication of the UEFI boot manager layer. You'll have multiple bootloaders fighting to load multiple operating systems all on top of the whole UEFI boot manager mechanism which is just throwing a whole bunch of other variables into the equation.
This is not a prospect filling the mind of anyone who's had to think about it with joy.
Still, it's important to recognize that the sins of UEFI in this area are sins of omission - they are not sins of commission, and they're not really the result of evil intent on anyone's part. The entity you should really be angry with if you have an idiotic system firmware that doesn't give you good access to the UEFI boot manager mechanism is not the UEFI forum, or Microsoft, and it certainly isn't Fedora and even more certainly isn't me ;). The entity you should be angry at is your system/motherboard manufacturer and the goddamn incompetents they hired to write the firmware, because the UEFI spec makes it really damn clear to anyone with two brain cells to rub together that it would be a very good idea to provide some kind of useful user interface to the UEFI boot manager, and any firmware which doesn't do so is crap code by definition. Yes, the UEFI forum should've realized that firmware engineers couldn't code their way out of a goddamned paper bag and just ordered them to do so, but still, it's ultimately the firmware engineers who should be lined up against the nearest wall.
Wait, we can simplify that. "Any firmware is crap code". Usually pretty accurate.
Secure Boot
So now we come, finally, to Secure Boot.
Secure Boot is not magic. It's not complicated. OK, that's a lie, it's incredibly complicated, but the theory isn't very complicated. And no, Secure Boot itself is not evil. I am entirely comfortable stating this as a fact, and you should be too, unless you think GPG is evil.
Secure Boot is defined in chapter 28 of the UEFI spec (2.4a, anyway). It's actually a pretty clever mechanism. But what it does can be described very, very simply. It says that the firmware can contain a set of signatures, and refuse to run any EFI executable which is not signed with one of those signatures.
That's it. Well, no, it really isn't, but that's a reasonably acceptable simplification. Security is hard, so there are all kinds of wibbly bits to implementing a really secure bootchain using Secure Boot, and mjg59 can tell you all about them, or you can pour another large shot of gin and read the whole of chapter 28. But that's the basic idea.
Using public key cryptography to verify the integrity of something is hardly a radical or evil concept. Pretty much all Linux distributions depend on it - we sign our packages and have our package managers go AWOOGA AWOOGA if you try to install a package which isn't signed with one of our keys. This isn't us being evil, and I don't think anyone's ever accused an OS of being evil for using public key cryptographic signing to establish trust in this way. Secure Boot is literally this exact same perfectly widely accepted mechanism, applied to the boot chain. Yet because a bunch of journalists wildly grasped the wrong end of the stick, it's widely considered to be slightly more evil than Hitler.
Secure Boot, as defined in the UEFI spec, says nothing at all about what the keys the firmware trusts should be, or where they should come from. I'm not going to go into all the goddamn details, because it gets stultifyingly boring and this post is too long already. But the executive summary is that the spec is utterly and entirely about defining a mechanism for doing cryptographic verification of a boot chain. It does not really even consider any kind of icky questions about the policy for doing so. It does nothing evil. It is as flexible as it could reasonably be, and takes care to allow for all the mechanisms involved to be configurable at multiple levels. The word 'Microsoft' is not mentioned. It is not in any way, shape, or form a secret agenda for Microsoft's domination of the world. If you doubt this, at the very bloody least, go and read it. I've given you all the necessary pointers. There is literally not a single legitimate reason I can think of for anyone to be angry with the idea "hey, it'd be neat if there was a mechanism for optional cryptographic verification of bootloader code in this firmware specification". None. Not one.
Secure Boot in the real world
Most of the unhappiness about Secure Boot is not really about Secure Boot the mechanism - whether the people expressing that unhappiness think it is or not - but about specific implementations of Secure Boot in the real world.
The only one we really care about is Secure Boot as it's implemented on PCs shipped with Microsoft Windows 8 or higher pre-installed.
Microsoft has these things called the Windows Hardware Certification Requirements. There they are. They are not Top Secret, Eyes Only, You Will Be Fed To Bill Gates' Sharks After Reading - they're right there on the Internet for anyone to read.
If you want to get cheap volume licenses of Windows from Microsoft to pre-install on your computers and have a nice "reassuring" 'Microsoft Approved!' sticker or whatever on the case, you have to comply with these requirements. That's all the force they have: they are not actually a part of the law of the United States or any other country, whatever some people seem to believe. Bill Gates cannot feed you to his sharks if you sell a PC that doesn't comply with these requirements, so long as you don't want a cheap copy of Windows to pre-install and a nice sticker. There is literally no requirement for a PC sold outside the Microsoft licensing program to configure Secure Boot in any particular way, or include Secure Boot at all. A PC that claims to have a UEFI 2.2 or later compliant firmware must implement Secure Boot, but can ship with it configured in literally absolutely any way it pleases (including turned off).
If you're going to have very loud opinions about Secure Boot, you have zero excuse for not going and reading the Microsoft certification requirements. Right now. I'll wait. You can search for "Secure Boot" to get to the relevant bit. It starts at "System.Fundamentals.Firmware.UEFISecureBoot".
You should read it. But here is a summary of what it says.
Computers complying with the requirements must:
- Ship with Secure Boot turned on (except for servers)
- Have Microsoft's key in the list of keys they trust
- Disable BIOS compatibility mode when Secure Boot is enabled (actually the UEFI spec requires this too, if I read it correctly)
- Support signature blacklisting
x86 computers complying with the requirements must additionally:
-
Allow a physically present person to disable Secure Boot
-
Allow a physically present person to enable Custom Mode, and modify the list of keys the firmware trusts
ARM computers complying with the requirements must additionally:
-
NOT allow a physically present person to disable Secure Boot
-
NOT allow a physically present person to enable Custom Mode, and modify the list of keys the firmware trusts
Yes. You read that correctly. The Microsoft certification requirements, for x86 machines, explicitly require implementers to give a physically present user complete control over Secure Boot - turn it off, or completely control the list of keys it trusts. Another important note here is that while the certification requirements state that the out-of-the-box list of trusted keys must include Microsoft's key, they don't say, for e.g., that it must not include any other keys. The requirements explicitly and intentionally allow for the system to ship with any number of other trusted keys, too.
These requirements aren't present entirely out of the goodness of Microsoft's heart, or anything - they're present in large part because other people explained to Microsoft that if they weren't present, it'd have a hell of a lawsuit on its hands2 - but they are present. Anyone who actually understands UEFI and Secure Boot cannot possibly read the requirements any other way, they are extremely clear and unambiguous. They both clearly intend to and succeed in ensuring the owner of a certified system has complete control over Secure Boot.
If you have an x86 system that claims to be Windows certified but does not allow you to disable Secure Boot, it is in direct violation of the certification requirements, and you should certainly complain very loudly to someone. If a lot of these systems exist then we clearly have a problem and it might be time for that giant lawsuit, but so far I'm not aware of this being the case. All the x86-based, Windows-certified systems I've seen have had the 'disable Secure Boot' option in their firmwares.
Now, for ARM machines, the requirements are significantly more evil: they state exactly the opposite, that it must not be possible to disable Secure Boot and it must not be possible for the system owner to change the trusted keys. This is bad and wrong. It makes Microsoft-certified ARM systems into a closed shop. But it's worth noting it's no more bad or wrong than most other major ARM platforms. Apple locks down the bootloader on all iDevices, and most Android devices also ship with locked bootloaders.
If you're planning to buy a Microsoft-certified ARM device, be aware of this, and be aware that you will not be in control of what you can boot on it. If you don't like this, don't buy one. But also don't buy an iDevice, or an Android device with a locked bootloader (you can buy Android devices with unlocked or unlockable bootloaders, still, but you have to do your research).
As far as x86 devices go, though, right now, Microsoft's certification requirements actually explicitly protect your right to determine what can boot on your system. This is good.
Recommendations
The following are AdamW's General Recommendations On Managing System Boot, offered with absolutely no guarantees of accuracy, purity or safety.
-
If you can possibly manage it, have one OS per computer. If you need more than one OS, buy more computers, or use virtualization. If you can do this everything is very simple and it doesn't much matter if you have BIOS or UEFI firmware, or use UEFI-native or BIOS-compatible boot on a UEFI system. Everything will be nice and easy and work. You will whistle as you work, and be kind to children and small animals. All will be sweetness and light. Really, do this.
-
If you absolutely must have more than one OS per computer, at least have one OS per disk. If you're reasonably comfortable with how BIOS-style booting works and you don't think you need Secure Boot, it's pretty reasonable to use BIOS-compatible booting rather than UEFI-style booting in this situation on a UEFI-capable system. You'll probably have less pain to deal with and you won't really lose anything. With one OS per disk you can also mix UEFI-native and BIOS-compatible installations.
-
If you absolutely insist on having more than one OS per disk, understand everything written on this page, understand that you are making your life much more painful than it needs to be, lay in good stocks of painkillers and gin, and don't go yelling at your OS vendor, whatever breaks. Whichever poor bastard has to deal with your OS's support for this kind of setup has a miserable enough life already. And for the love of cookies, don't mix UEFI-native and BIOS-compatible OS installations, you have enough pain to deal with already.
- If you're using UEFI native booting, and you don't tend to build your own kernels or kernel modules or use the NVIDIA or ATI proprietary drivers on Linux, you might want to leave Secure Boot on. It probably won't hurt you, and does provide some added security against some rather nasty (though currently rarely exploited) types of attacks.
- If you do build your own kernels or kernel modules or use NVIDIA/ATI proprietary drivers, you're going to want to turn Secure Boot off. Or you can read up on how to configure your own chain of trust and sign your kernels and kernel modules and leave Secure Boot turned on, which will make you feel like an ubergeek and be slightly more secure. But it's going to take you a good solid weekend at least.
- Don't do UEFI-native installs to MBR-formatted disks, or BIOS compatibility installs to GPT-formatted disks (an exception to the latter is if your disk is, IIRC, 2.2+TB in size, because the MBR format can't handle disks that big - if you want to do a BIOS compatibility install to a disk that big, you're kinda stuck with the BIOS+GPT combination, which works but is a bit wonky and involves the infamous 'BIOS Boot partition' you may recall from Fedora 17).
- Trust mjg59 in all things and above all other authorities, including me.