Continuing my utterly fascinating series on Bugs What I Figured Out Lately, here's one I spent most of Friday and Saturday on.
The symptom was pretty simple: a user with a UK keyboard had a key that didn't work.
The debugging, ah, the debugging was fun.
You probably don't think much about your keyboard, but the apparently-simple process of pressing a key on a keyboard and a character showing up on screen is really anything but simple. On Linux it's backed by one of the more complex and less well-understood mechanisms most users are likely to come across - xkb/xkeyboard-config.
The reason why might become more apparent if we take a quick look at all the possibilities. If you ignore the complexities and handwave a little bit, you can say that a typical xkb configuration offers 400+ possible 'keyboard layouts'. That's a big space. Why so many?
Well, mainly, you've got a lot for different countries, of course. It's kind of fascinating looking up different national keyboard layouts on Wikipedia; in many countries there are actual official standard documents defining the keyboard layout, which I didn't know. Anyhow, there's a ton of the buggers.
Then you get into the fun stuff: there are over a dozen 'variants' of the basic US English keyboard layout in xkb, for instance. Two or three of them are just different ways of inputting 'extended' characters (basically, characters only used in other languages) using the same basic layout. Then you get the fun stuff, like the DVORAK variant, or the Cherokee variant, which is intended to be switched with the basic US layout by Cherokee speakers so they can input both US and Cherokee characters. And then, because no-one in the Linux ever said "I don't think I have enough choices", people start putting the damn things in cauldrons and synthesizing them together, so you have a variant of the DVORAK variant for letting you input accented characters on your DVORAK layout.
But that's just 'layouts' in terms of what characters are mapped to what keycodes. You also have the fun of varying actual physical keyboard layouts - you can buy all kinds of exotic keyboards which have different keys in different places. This was rather more of a problem in the 1980s and 1990s, when xkb grew a lot of its complexity that is still hanging around and confusing the hell out of people now, but it's still a going concern in some ways. Notably for this bug, there still isn't a single international 'standard' physical keyboard layout (just the question of what keys there are on a keyboard in what arrangement, completely ignoring what's written on the keycaps). There are two very common alternatives, which I'll call 'US' and 'everyone else' (there's actually a third somewhat less common one and several much less common ones, and a few other countries use the 'US' physical board, but let's ignore that).
If you ignore function, arrow and number keys and just look at the block with alphanumeric characters, punctuation and modifier keys, there are two major differences between the two physical layouts. On a US keyboard the second row from the bottom has a Shift key on the far left, and then the first letter key on that row (which is 'Z' on a US keyboard). On the 'everyone else' keyboard, there are three keys in this space. On a UK keyboard there's still a shift key and a Z key, but the shift key is smaller and there's a key in the middle which is marked with a backslash and a broken pipe symbol. On other international keyboards the first key is almost always still a Shift key, but the other two might be different things, but the physical layout is the same. Over on the right hand side, the 'US' physical keyboard has a long enter key which is only a single row high, and a key above it (which is the backslash / pipe key on a US keyboard); on the 'everyone else' model, the Enter key is two rows high but less wide, and the other key is to the left of it on the third row instead of above it. Hard to describe, but if you look at a couple of pictures it's pretty obvious.
So (after 700 words!) back to the bug: for our poor reporter, who has a UK keyboard, the 'extra' key between Shift and Z - the backslash/pipe key - didn't (appear to) work. He pressed it, nothing seemed to happen. (UK users commonly use this key to enter, well, backslashes and pipes; there are actually other keys on the UK layout that can enter these characters, but they're less conveniently situated).
After hearing his report, I went haring off and learned a hell of a lot more about xkb than I had learned before, and possibly more than I actually wanted to know. I developed a neat elegant theory which explained all the apparent symptoms of the bug, which turned out to be completely wrong. This is something that happens frequently in debugging. At least to me. Maybe the rest of you are much smarter and don't have this problem. But don't get discouraged! You almost certainly learned something in coming up with your theory, and it will probably be useful to you in future.
My elegant, wrong theory revolved around an xkb setting. Well, actually, two xkb settings, one a 'real' one and one an abstraction. I am not going to explain the internals of xkb here because OH GOD NO, but as an example of the horrors you will find if you delve into it: you may be somewhat familiar with the most common way of configuring xkb, which is to fiddle with a small set of parameters:
XkbModel
XkbLayout
XkbVariant
XkbOptions
It is, perhaps, instructive to the complexity of xkb internals to know that these don't exactly really exist - or rather, they're not really how xkb thinks about things. Internally, xkb thinks about keycodes, types, compat, symbols and geometry. It is a fairly little-known fact that you can actually specify an xkb config by specifying each of these directly (as XkbKeycodes, XkbTypes, XkbCompat etc etc). When you specify a config in the Model, Layout, Variant, Options format, what you are in fact doing is telling xkb to use a given set of rules to transform those options into a set of keycodes, types, compat, symbols and geometry settings. Essentially, xkb heard you liked configuration, dawg, so it wrapped its configuration scheme in a configuration scheme you can configure while you configure.
So, I had gotten about 60% of the xkb cluestick, and I started to latch on to the concepts of 'geometry' and 'model', without quite understanding that it was part of one of xkb's config schemes and the concept of a 'model' was part of the other. But it was at least becoming apparent to me that in general the xkb config you get from Fedora's installer or desktop tools did not specify either model or geometry, and that these concepts appeared to include the question of which physical keyboard layout is in use. It also was beginning to seem to me that, if you didn't specify this explicitly, xkb would assume the US physical keyboard.
All of this is actually true; I wasn't wrong. It just wasn't the source of the bug. But you can see why I thought it was, right? Surely, if xkb thinks we're using a US physical keyboard, and the US physical keyboard doesn't have that key at all, that's why it's not working, right?! There was even corroborating evidence: GNOME can render a preview of any given keyboard layout. If you pick the UK keyboard layout in GNOME and look at the preview, that key is missing (assuming you have a 'normal' Fedora X config, where xkb is assuming the US physical keyboard). If you then manually change your X config to specify the international keyboard model (which you can do by specifying XkbModel "pc105"), the preview does show the key. Pretty damning, right?
Well, as it turns out, no. Though I'm damn well giving myself a pass for thinking so. But as I dug deeper (and got some invaluable help from Rui Matos), it turns out that the concept of 'geometry' - which is what xkb calls the actual physical key layout - is not that important to xkb at all. xkb does not really use it, in terms of it being a factor in what keycodes are translated to what keysyms (actual on-screen characters...more or less), at all. It's actually only used for...rendering preview images of keyboard layouts.
@()^*)*@#(^&*!&)*!(&$!)(*$DAMNIT, xkb.
As noted above, the concept of a 'model' is actually an abstraction of the 'real' underlying configuration items. If you set a keyboard 'model' in your xkb config, what that actually means depends on the model you set, but for the models that are just representations of 'typical' physical keyboard layouts (pc101, pc102, pc104, pc105), it just results in the appropriate 'geometry' being set, and doesn't change any of the other config settings (keycodes, types, compat, symbols) at all. So it really doesn't matter.
This was confirmed with the bug reporter: changing model didn't fix his key. So my beautiful elegant theory was dead. Ah, well.
Fortunately, all this crap I'd learned about xkb internals made it 'easy' to diagnose the real problem, once I got the info necessary. If you've read this far, congrats, because here's something you may find useful. In debugging a bug of this type, the information you're going to really really want is this: the output of 'setxkbmap -print', and the output shown on the console when you run 'xev' and press the key in question. So, here's what I got from the bug reporter:
setxkbmap -print
xkb_keymap {
xkb_keycodes { include "evdev+aliases(qwerty)" };
xkb_types { include "complete" };
xkb_compat { include "complete" };
xkb_symbols { include "pc+gb+us:2+inet(evdev)+level5(lsgt_switch_lock)" };
xkb_geometry { include "pc(pc102)" };
};
KeyPress event, serial 36, synthetic NO, window 0x2200001,
root 0x82, subw 0x0, time 695097, (367,321), root:(369,408),
state 0x1, keycode 94 (keysym 0xfe11, ISO_Level5_Shift), same_screen YES,
XLookupString gives 0 bytes:
XmbLookupString gives 0 bytes:
XFilterEvent returns: False
I might have figured it out just from that even before doing a deep dive into xkb, but it sure seemed obvious afterwards.
setxkbmap -print in particular is a really useful bit of data: it tells you exactly what the 'real' xkb parameters are set to right at that moment. No abstractions, no muss, no fuss: that's your 'real' xkb config right there. The setting for keycodes is sane and normal (that defines 'what are we expecting to see from the underlying kernel driver', which these days is just about always evdev; if it's set to the wrong thing you'll get complete gibberish, on the 'garbage in, garbage out' principle). types and compat, also boring. geometry, as we've established, unimportant (though for the record, 'pc102' is the international-style physical keyboard with no windows keys). The interesting bit is symbols - it usually is, because that's the bit that's doing most of the grunt work. The stuff listed there is basically 'the rules being used to determine what keycodes mean what keysyms'.
Those first four are pretty normal, but that "level5(lsgt_switch_lock)" is not at all, I hadn't actually seen it before. The 'lsgt' was a big warning flag: the 'missing key' in question is referred to as 'lsgt' internally in xkb (it means 'lesser/greater', because if you set the US layout on an international physical keyboard, that key gets mapped as the "lesser than" and "greater than" symbols). You might also, if you have sharp eyes, have spotted something apparently related in the xev output:
(keysym 0xfe11, ISO_Level5_Shift)
if so, congratulations, because it definitely is related. If you're looking at xev output and trying to figure out something related to a keypress, that part of the output is probably what you're going to find useful:
keycode 94 (keysym 0xfe11, ISO_Level5_Shift)
what that's telling us is that the key that was pressed has the 'keycode' 94, and that keycode is mapped by the currently-operational xkb rules to the 'keysym' 0xfe11, which - if you don't speak xkb as a native language - is handily explained to be "ISO_Level5_Shift". What we would be expecting if the key was working properly would be (keysym 0x5c, backslash). So what the xev output tells us is that the key actually is doing something, but not what we expected.
It happens that what it's doing is something quite subtle: "level5_shift" basically means 'this is a modifier key which will shift to the fifth level of characters while it's pressed'. The first level of characters is what you get when you just press a key with no modifiers, the second level is what you get when you press a key while holding Shift, the third level is what you get when you press a key while holding a third level modifier key, the fourth level is the third level shifted, the fifth level is yet ANOTHER level, and the sixth level is the fifth level shifted. Obviously, the point of the third, fourth, fifth, sixth levels is to let you input more than however many characters can possibly be input with all the keys on the keyboard with and without the shift modifier key.
In practice you can enter a hell of a lot of characters with just four levels, so the fifth level rarely gets used at all, and as the key was set to behave like a 'shift' key - it only did something if you held it down and pressed another key - the reporter could be forgiven for thinking it wasn't doing anything at all. It probably wouldn't have done much even if he had held it down and pressed another key, as I don't think the UK layout has a fifth level. Hell, I'm not sure it has a third (though some of its variants do).
So as it transpires, the setting "level5(lsgt_switch_lock)" was causing the key to act as a level 5 modifier key instead of whatever it would otherwise have done, and that's why the reporter thought it wasn't doing anything. I'd been poking other levels of the keyboard input stack too, so I knew the most obvious places to look for that setting being requested: an X config snippet, or GNOME's keyboard config settings.
In GNOME, the gsettings keys under org/gnome/desktop/input-sources define what GNOME wants the xkb config to be (and therefore, almost certainly, what it actually is when you're running GNOME, unless you've got some script changing them after GNOME starts, or you just changed them yourself with setxkbmap). The key 'xkb-options' specifies XkbOptions. Sure enough, the reporter had "level5(lsgt_switch_lock)" set in his xkb-options key. As soon as he unset the key, his \ key started working.
Whew! Sorry I've rambled again, but I hope this has illustrated a couple of things: it can take a lot of background knowledge to quickly and confidently diagnose a problem which from a superficial description seems simple, and it is not unusual to look at a problem carefully and conscientiously, come up with an explanation that appears entirely internally consistent and explains all the symptoms of the problem and even appears to be corroborated by other data, and then find out that that explanation is entirely wrong. If this happens to you, don't worry. It's probably not your fault. It's just...computers.
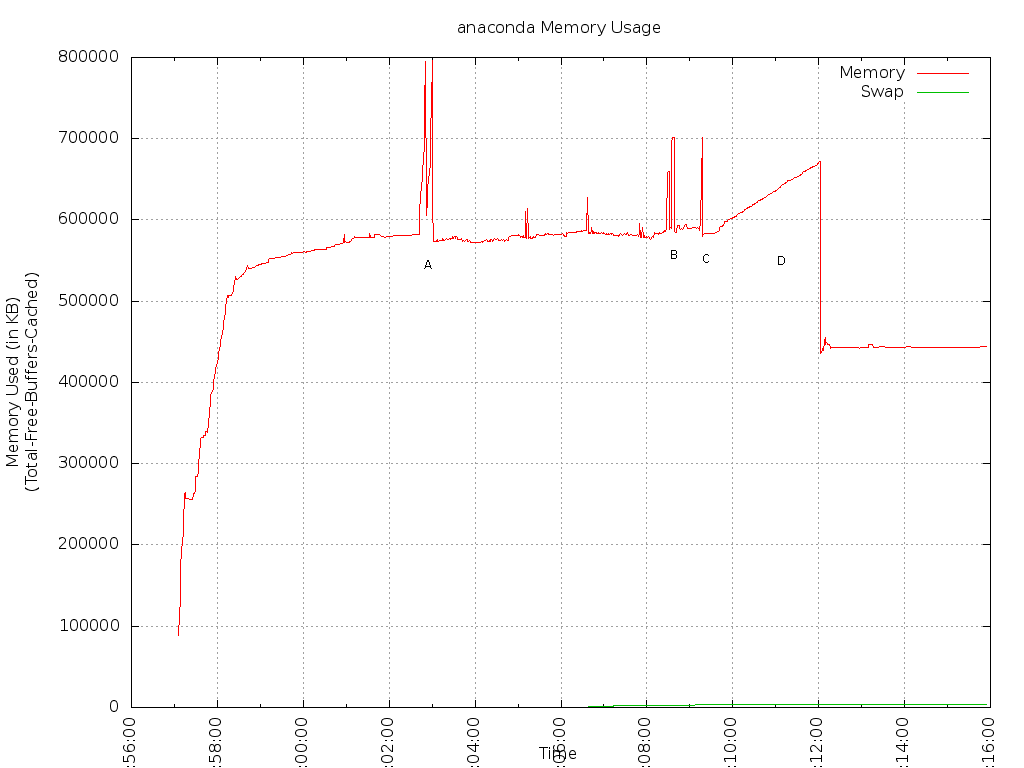 As Chris did, I've annotated the spikes (although much more messily than he did).
So, what do we see? It's a bit hard to see in this graph as I blew through the install process very quickly, but I just ran another test, and if I complete the necessary spokes and leave the UI sitting at the hub screen before actually kicking off an install, the 'background level' of anaconda itself is 329MB. In Chris' graph, this 'background level' before package installation kicks in looks like it's around 200MB. However, oldUI was very different from newUI, and most of the difference there may be accounted for by the fact that we've already fired up storage and repository configuration code at this point.
The 'background level' during package installation - where the line sort of mostly sits aside from spikes - is around 590MB in my data. In Chris' F15 test, it looks like it was around 520MB-530MB (eyeballing it). So usage has increased about 60-70MB there.
The spikes are as follows:
A - sepolgen-ifgen running during install of policycoreutils-devel package (spikes to 796MB)
B and C - both gtk-update-icon-cache, running during %posttrans I believe. See
As Chris did, I've annotated the spikes (although much more messily than he did).
So, what do we see? It's a bit hard to see in this graph as I blew through the install process very quickly, but I just ran another test, and if I complete the necessary spokes and leave the UI sitting at the hub screen before actually kicking off an install, the 'background level' of anaconda itself is 329MB. In Chris' graph, this 'background level' before package installation kicks in looks like it's around 200MB. However, oldUI was very different from newUI, and most of the difference there may be accounted for by the fact that we've already fired up storage and repository configuration code at this point.
The 'background level' during package installation - where the line sort of mostly sits aside from spikes - is around 590MB in my data. In Chris' F15 test, it looks like it was around 520MB-530MB (eyeballing it). So usage has increased about 60-70MB there.
The spikes are as follows:
A - sepolgen-ifgen running during install of policycoreutils-devel package (spikes to 796MB)
B and C - both gtk-update-icon-cache, running during %posttrans I believe. See